
Hi,
After recreating whisper databases I can see some of the graphs. Now I have another problém - not all statistics are collected! I checked graphite and it displays only few of them. The nav systém have ran for a day now, so I would expect, that it is enough time to collect all informations.
In the screenshot (made from graphite webinterface) you can see various collected statistics - they are not even the same for various ports.
There are no problems reported for this device in the ipdevpoll.log
Any ideas?
Thanks
Mat
-----Original Message----- From: nav-users-request@uninett.no [mailto:nav-users-request@uninett.no] On Behalf Of Martin.Jaburek@cah.cz Sent: Tuesday, March 25, 2014 4:05 PM To: John-Magne Bredal; Morten Brekkevold Cc: nav-users@uninett.no Subject: RE: New to nav system
Hi,
I'm stupid. I forget to update etc/graphite/storage-schemas.conf and etc/graphite/storage-aggregation.conf.
I deleted all whisper databases and hopefully it will be much better now.
Mat
-----Original Message----- From: JABUREK Martin Sent: Tuesday, March 25, 2014 3:55 PM To: 'John-Magne Bredal'; Morten Brekkevold Cc: nav-users@uninett.no Subject: RE: New to nav system
Hi,
Regarding the bug - I'm using 4.0b5 right now. Is the patch also applicable for this version?
Restarting ipdevpoll does help, but not for the first time. I had to restart
it repeatadly (I did it due to other errors and then I mention, that it corrected it)
Regarding the graphs I think there is some problem with graphing/storing data? I attached three pictures: Ten correct.png ... correct graph from rrdtools Ten graphite.png ... graph collected from graphite web interface Ten nav.png ... graph collected from nav interface
It seems to me, that graphite stores too few datapoints, I tried to dump raw
data and I get this:
nav.devices.DEVICE.ports.Te1_1.ifInOctets,2014-03-25 09:16:00, nav.devices.DEVICE.ports.Te1_1.ifInOctets,2014-03-25 09:17:00, nav.devices.DEVICE.ports.Te1_1.ifInOctets,2014-03-25 09:18:00, nav.devices.DEVICE.ports.Te1_1.ifInOctets,2014-03-25 09:19:00,6302589367015099.0 nav.devices.DEVICE.ports.Te1_1.ifInOctets,2014-03-25 09:20:00, nav.devices.DEVICE.ports.Te1_1.ifInOctets,2014-03-25 09:21:00, nav.devices.DEVICE.ports.Te1_1.ifInOctets,2014-03-25 09:22:00, nav.devices.DEVICE.ports.Te1_1.ifInOctets,2014-03-25 09:23:00,6302603784021890.0 nav.devices.DEVICE.ports.Te1_1.ifInOctets,2014-03-25 09:24:00, nav.devices.DEVICE.ports.Te1_1.ifInOctets,2014-03-25 09:25:00, nav.devices.DEVICE.ports.Te1_1.ifInOctets,2014-03-25 09:26:00, nav.devices.DEVICE.ports.Te1_1.ifInOctets,2014-03-25 09:27:00, nav.devices.DEVICE.ports.Te1_1.ifInOctets,2014-03-25 09:28:00,6302617817392692.0 nav.devices.DEVICE.ports.Te1_1.ifInOctets,2014-03-25 09:29:00, nav.devices.DEVICE.ports.Te1_1.ifInOctets,2014-03-25 09:30:00, nav.devices.DEVICE.ports.Te1_1.ifInOctets,2014-03-25 09:31:00, nav.devices.DEVICE.ports.Te1_1.ifInOctets,2014-03-25 09:32:00, nav.devices.DEVICE.ports.Te1_1.ifInOctets,2014-03-25 09:33:00, nav.devices.DEVICE.ports.Te1_1.ifInOctets,2014-03-25 09:34:00,6302631305894654.0 nav.devices.DEVICE.ports.Te1_1.ifInOctets,2014-03-25 09:35:00, nav.devices.DEVICE.ports.Te1_1.ifInOctets,2014-03-25 09:36:00, nav.devices.DEVICE.ports.Te1_1.ifInOctets,2014-03-25 09:37:00, nav.devices.DEVICE.ports.Te1_1.ifInOctets,2014-03-25 09:38:00,6302639660718015.0 nav.devices.DEVICE.ports.Te1_1.ifInOctets,2014-03-25 09:39:00, nav.devices.DEVICE.ports.Te1_1.ifInOctets,2014-03-25 09:40:00, nav.devices.DEVICE.ports.Te1_1.ifInOctets,2014-03-25 09:41:00, nav.devices.DEVICE.ports.Te1_1.ifInOctets,2014-03-25 09:42:00, nav.devices.DEVICE.ports.Te1_1.ifInOctets,2014-03-25 09:43:00,6302653053594991.0 nav.devices.DEVICE.ports.Te1_1.ifInOctets,2014-03-25 09:44:00, nav.devices.DEVICE.ports.Te1_1.ifInOctets,2014-03-25 09:45:00,
Shouldn't I set up scheme for carbon database to await only 5 min collections? It seems to me, that after applying derivative function it show nothing due to empty datapoints.
Mat -----Original Message----- From: John-Magne Bredal [mailto:john.m.bredal@uninett.no] Sent: Monday, March 24, 2014 2:36 PM To: JABUREK Martin; Morten Brekkevold Cc: nav-users@uninett.no Subject: Re: New to nav system
On 03/24/2014 10:51 AM, Martin.Jaburek@cah.cz wrote:
I modified the unknown OIDs and now I am able to collect information from boxes.
Great!
Now I have these issues:
- graphs showing throughput - there are only empty graphs on port info
tabs. I think that backend should be fine, because I can see some graphs (for example SystemMetrics/CPU are all fine) Maybe it is related to a fetch error from statistics pane. (see screenshot)
See below.
2014-03-24 04:59:09,673 [WARNING plugins.dnsname.dnsname] [inventory IP2] Box dnsname has changed from u 'IP2' to 'DNS2' When I edit device it gets the right name, but it keep reporting only IP. This started when I added unknown device and now I corrected it. So I have other devices with right DNS names as sysnames.
We think this may be related to this bug: https://bugs.launchpad.net/nav/+bug/1292513 . This has been fixed and will be part of the next release.
The port statistics are probably being stored using the IP-address not the DNS name of the IP Device. You can verify this by browsing the Graphite Web interface and see which nodes are present under nav.devices.
Try restarting ipdevpoll. This may fix your current problem.
- how can I change the look of graphs? I'm getting black backgrounded
graphs which are really ugly on white background.
In the graphite configuration directory (perhaps /opt/graphite/conf), copy the file graphTemplates.conf.example to graphTemplates.conf. Then edit it and add the following:
[nav] background = white foreground = black
The work done is really amazing. I look forward when I have it finally fully up.
Thank you! :)
-- John-Magne Bredal UNINETT AS

On Wed, 26 Mar 2014 08:27:43 +0000 "Martin.Jaburek@cah.cz" Martin.Jaburek@cah.cz wrote:
After recreating whisper databases I can see some of the graphs. Now I have another problém - not all statistics are collected! I checked graphite and it displays only few of them. The nav systém have ran for a day now, so I would expect, that it is enough time to collect all informations.
In the screenshot (made from graphite webinterface) you can see various collected statistics - they are not even the same for various ports.
Did you configure Carbon's "MAX_CREATES_PER_MINUTE", as per. NAV's install instructions?
Carbon's default limit is maximum 50 new Whisper files created per minute; when more than 50 metrics are received within a 1 minute window, only the 50 first will be created by Carbon, the rest will be silently ignored.
Depending on the number of devices you have seeded into NAV, a setting of 50 may cause Carbon to take from many hours to several days to create Whisper files for all the metrics that NAV is throwing at it.
I checked it and it was indeed set to 50. I changed it to inf and I restarted nav and carbon.
Now I can see many new databases being created. Thank you very much for such swift response.
It's a shame, that carbon ignores exceeding creation requests silently (I even checked the creates.log for new databases)
Mat
-----Original Message----- From: Morten Brekkevold [mailto:morten.brekkevold@uninett.no] Sent: Wednesday, March 26, 2014 1:16 PM To: JABUREK Martin Cc: John-Magne Bredal; nav-users@uninett.no Subject: Re: Problem retrieving port statistics
On Wed, 26 Mar 2014 08:27:43 +0000 "Martin.Jaburek@cah.cz" Martin.Jaburek@cah.cz wrote:
After recreating whisper databases I can see some of the graphs. Now I have another problém - not all statistics are collected! I checked graphite and it displays only few of them. The nav systém have ran for a day now, so I would expect, that it is enough time to collect all informations.
In the screenshot (made from graphite webinterface) you can see various collected statistics - they are not even the same for various ports.
Did you configure Carbon's "MAX_CREATES_PER_MINUTE", as per. NAV's install instructions?
Carbon's default limit is maximum 50 new Whisper files created per minute; when more than 50 metrics are received within a 1 minute window, only the 50 first will be created by Carbon, the rest will be silently ignored.
Depending on the number of devices you have seeded into NAV, a setting of 50 may cause Carbon to take from many hours to several days to create Whisper files for all the metrics that NAV is throwing at it.
-- Morten Brekkevold UNINETT
On Wed, 26 Mar 2014 12:26:43 +0000 "Martin.Jaburek@cah.cz" Martin.Jaburek@cah.cz wrote:
I checked it and it was indeed set to 50. I changed it to inf and I restarted nav and carbon.
Now I can see many new databases being created. Thank you very much for such swift response.
No problem, I'm glad you've sorted it out :)
It's a shame, that carbon ignores exceeding creation requests silently (I even checked the creates.log for new databases)
The feature is quite deliberate. AFAIK, Carbon/graphite was built for storing massive amounts of metrics from a cloud provider, where each individual metric wasn't necessarily very significant (i.e. cloud servers come and go all the time; the individual server doesn't matter in the grand scheme of things, the provided service level does).
The feature is there to not completely overload the I/O system of the Carbon server in such a setting. In the smaller context of a single NAV installation, individual metrics matter more, and the default setting of 50 becomes too small, given that the majority of metrics are only delivered once every five minutes, not every 10 seconds.
Hi,
Now I am able to collect all information needed.
But I still have a problém with collected data - there are very often gaps in graphs.
I moved whisper databases on memory filesystem and now the load does not exceed 1 (2 CPU machine)
I checked ipdevpoll.log for errors but nothing there.
I am collecting now 56 125 metrics - I just counted whisper databases in nav.* context. And it is about an half of the network monitored.
Any idea where could be a bottleneck now and how to figure it out? Any suggestions to further tweak the systém?
Mat -----Original Message----- From: Morten Brekkevold [mailto:morten.brekkevold@uninett.no] Sent: Wednesday, March 26, 2014 2:34 PM To: JABUREK Martin Cc: John-Magne Bredal; nav-users@uninett.no Subject: Re: Problem retrieving port statistics
On Wed, 26 Mar 2014 12:26:43 +0000 "Martin.Jaburek@cah.cz" Martin.Jaburek@cah.cz wrote:
I checked it and it was indeed set to 50. I changed it to inf and I restarted nav and carbon.
Now I can see many new databases being created. Thank you very much for such swift response.
No problem, I'm glad you've sorted it out :)
It's a shame, that carbon ignores exceeding creation requests silently (I even checked the creates.log for new databases)
The feature is quite deliberate. AFAIK, Carbon/graphite was built for storing massive amounts of metrics from a cloud provider, where each individual metric wasn't necessarily very significant (i.e. cloud servers come and go all the time; the individual server doesn't matter in the grand scheme of things, the provided service level does).
The feature is there to not completely overload the I/O system of the Carbon server in such a setting. In the smaller context of a single NAV installation, individual metrics matter more, and the default setting of 50 becomes too small, given that the majority of metrics are only delivered once every five minutes, not every 10 seconds.
-- Morten Brekkevold UNINETT
On Thu, 27 Mar 2014 08:37:51 +0000 "Martin.Jaburek@cah.cz" Martin.Jaburek@cah.cz wrote:
Now I am able to collect all information needed.
But I still have a problém with collected data - there are very often gaps in graphs.
Which graphs have gaps? Port metrics? System metrics? All of them?
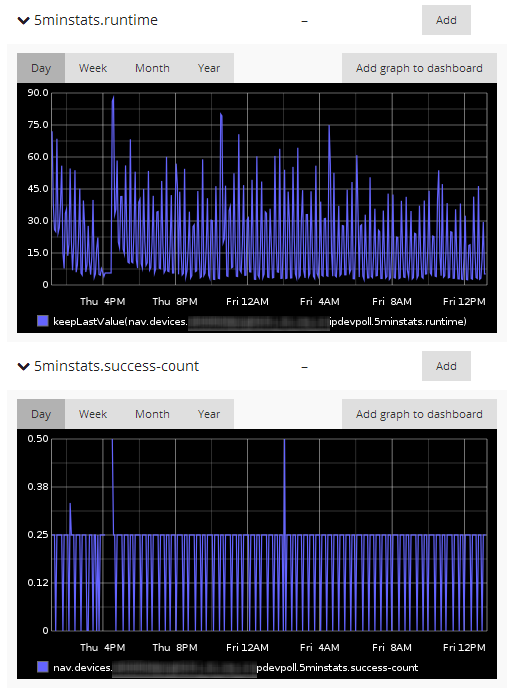
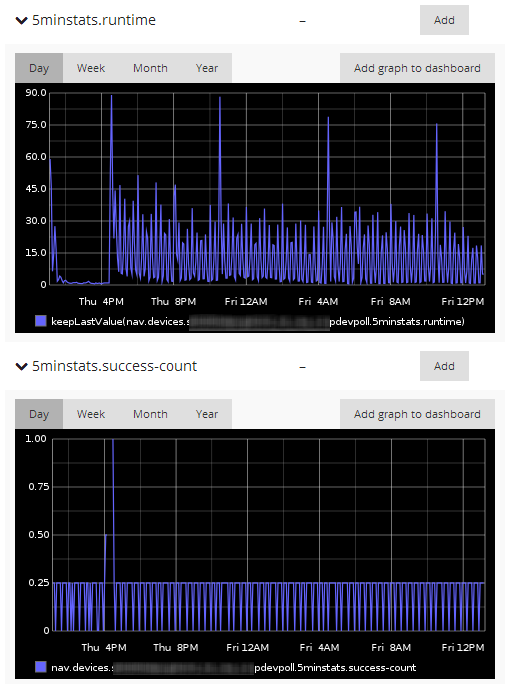
How many devices are you monitoring, and what does the runtime of the various ipdevpoll jobs look like?
If the 1minstats job is spending more than 1 minute to complete for any device, there may be gaps its graphs, 5 minutes for the 5minstats job.
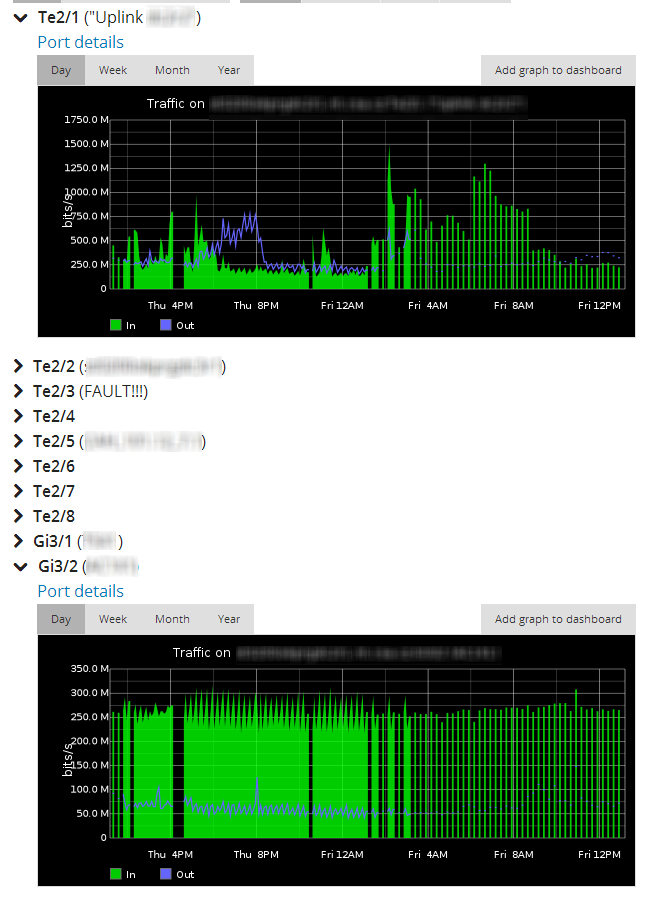
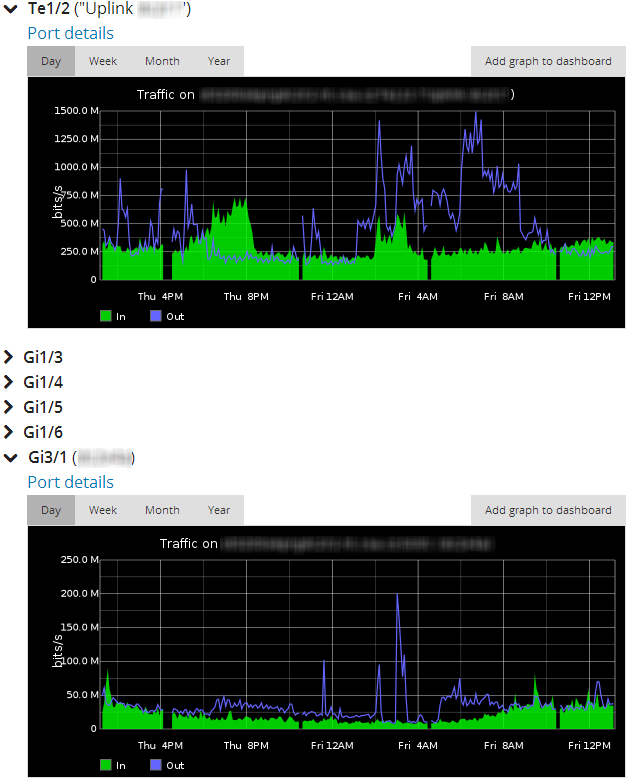
I solved my problém with moving databases to memory - it reduces load on machine and now it is ok. But I am still experiencing gaps on some graphs. There is one device which suffers from it most - see attached graphs. (graphs are from 2 devices - one OK and the other with GAPS)
Gaps are only in port metrics graphs - they are at exactly the same time on all ports on given device.
Systém metrics are just fine on this device.
I checked the 5min graph of ipdevpoll systém metrics and it shows 100 at peak times, what I assume are only nearly 2 minutes.
I'm monitoring about 140 devices right now with nav.
I think that it is much correlated to my yesterday upgrade to 4.0.0 (from 4.0b5).
Since then I can also see attached errors. They were not there when I was on version 4.0b5.
It happens only on cisco catalyst 4500/6500 and one type of 3560E. (I have many 3750 but, there is no problém at all) and causes inventory jobs to fail.
Brgds
Mat
-----Original Message----- From: nav-users-request@uninett.no [mailto:nav-users-request@uninett.no] On Behalf Of Morten Brekkevold Sent: Friday, March 28, 2014 10:36 AM To: JABUREK Martin Cc: nav-users@uninett.no Subject: Re: Problem retrieving port statistics
On Thu, 27 Mar 2014 08:37:51 +0000 "Martin.Jaburek@cah.cz" Martin.Jaburek@cah.cz wrote:
Now I am able to collect all information needed.
But I still have a problém with collected data - there are very often gaps in graphs.
Which graphs have gaps? Port metrics? System metrics? All of them?
How many devices are you monitoring, and what does the runtime of the various ipdevpoll jobs look like?
If the 1minstats job is spending more than 1 minute to complete for any device, there may be gaps its graphs, 5 minutes for the 5minstats job.
-- Morten Brekkevold UNINETT
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
On Fri, 28 Mar 2014 12:38:18 +0000 "Martin.Jaburek@cah.cz" Martin.Jaburek@cah.cz wrote:
Gaps are only in port metrics graphs - they are at exactly the same time on all ports on given device.
Systém metrics are just fine on this device.
I checked the 5min graph of ipdevpoll systém metrics and it shows 100 at peak times, what I assume are only nearly 2 minutes.
The gaps in your graphs appear to happen every 6 hours, which seems to correlate with the inventory job interval. You might want to check your ipdevpoll.log for timeout errors.
You may do well to adjust the SNMP parameters in ipdevpoll.conf. On several installations, we've experienced that the default timeout is too low and the default max-repetitions value is too high (some devices tend to freak out and slow down when they get a GET-BULK request for 50 values). Often, we end up setting max-repetitions at or below 10.
You could also reduce the max_concurrent_jobs option, so ipdevpoll won't try to talk to all your devices at the exact same time.
Since then I can also see attached errors. They were not there when I was on version 4.0b5.
It happens only on cisco catalyst 4500/6500 and one type of 3560E. (I have many 3750 but, there is no problém at all) and causes inventory jobs to fail.
[snip]
File "/usr/local/nav/lib/python/nav/mibs/entity_mib.py", line 163, in get_chassis if self.is_chassis(entity)] File "/usr/local/nav/lib/python/nav/mibs/entity_mib.py", line 125, in is_chassis return e['entPhysicalClass'] == 'chassis' exceptions.KeyError: 'entPhysicalClass'
It's this bug: https://bugs.launchpad.net/nav/+bug/1300117
The fix has been patched into the Debian packages already, but this is serious enough to warrant new official releases tomorrow.
Hi,
I'm actually hitting this problém with slow answering devices. Unfortunately they form the backbone...
I'm trying these new settings and I will see if it helped: max_concurrent_jobs = 300 timeout = 20 max-repetitions = 5
and topology job scheduled only once an hour: [job_topo] interval: 60m plugins: cam lldp cdp description: The topo job collects data necessary for detecting the network topology, like switch forwarding tables (CAM) and LLDP and CDP neighboring data
I will let you know, if it helped.
Brgds
Mat
-----Original Message----- From: nav-users-request@uninett.no [mailto:nav-users-request@uninett.no] On Behalf Of Morten Brekkevold Sent: Wednesday, April 02, 2014 9:34 AM To: JABUREK Martin Cc: nav-users@uninett.no Subject: Re: Problem retrieving port statistics
On Fri, 28 Mar 2014 12:38:18 +0000 "Martin.Jaburek@cah.cz" Martin.Jaburek@cah.cz wrote:
Gaps are only in port metrics graphs - they are at exactly the same time on all ports on given device.
Systém metrics are just fine on this device.
I checked the 5min graph of ipdevpoll systém metrics and it shows 100 at peak times, what I assume are only nearly 2 minutes.
The gaps in your graphs appear to happen every 6 hours, which seems to correlate with the inventory job interval. You might want to check your ipdevpoll.log for timeout errors.
You may do well to adjust the SNMP parameters in ipdevpoll.conf. On several installations, we've experienced that the default timeout is too low and the default max-repetitions value is too high (some devices tend to freak out and slow down when they get a GET-BULK request for 50 values). Often, we end up setting max-repetitions at or below 10.
You could also reduce the max_concurrent_jobs option, so ipdevpoll won't try to talk to all your devices at the exact same time.
Since then I can also see attached errors. They were not there when I was on version 4.0b5.
It happens only on cisco catalyst 4500/6500 and one type of 3560E. (I have many 3750 but, there is no problém at all) and causes inventory jobs to fail.
[snip]
File "/usr/local/nav/lib/python/nav/mibs/entity_mib.py", line 163, in get_chassis if self.is_chassis(entity)] File "/usr/local/nav/lib/python/nav/mibs/entity_mib.py", line 125, in is_chassis return e['entPhysicalClass'] == 'chassis' exceptions.KeyError: 'entPhysicalClass'
It's this bug: https://bugs.launchpad.net/nav/+bug/1300117
The fix has been patched into the Debian packages already, but this is serious enough to warrant new official releases tomorrow.
-- Morten Brekkevold UNINETT
On Thu, 3 Apr 2014 14:41:19 +0000 "Martin.Jaburek@cah.cz" Martin.Jaburek@cah.cz wrote:
I'm actually hitting this problém with slow answering devices. Unfortunately they form the backbone...
I'm trying these new settings and I will see if it helped:
[snip]
I will let you know, if it helped.
Thanks, much appreciated :)
Hi,
So it did not help. Statistics just showed, that it ran for 11300 sec. It screwed all other switches.
I removed them from nav now.
Is it possible to do some lightweight monitoring (excluding LLDP and other extended functionality, just basic traffic monitoring) If it would help, then we can keep adding features (MAC, vlans, etc.)
Mat
-----Original Message----- From: Morten Brekkevold [mailto:morten.brekkevold@uninett.no] Sent: Monday, April 07, 2014 3:23 PM To: JABUREK Martin Cc: nav-users@uninett.no Subject: Re: Problem retrieving port statistics
On Thu, 3 Apr 2014 14:41:19 +0000 "Martin.Jaburek@cah.cz" Martin.Jaburek@cah.cz wrote:
I'm actually hitting this problém with slow answering devices. Unfortunately they form the backbone...
I'm trying these new settings and I will see if it helped:
[snip]
I will let you know, if it helped.
Thanks, much appreciated :)
On Tue, 8 Apr 2014 10:33:53 +0000 "martin.jaburek@cah.cz" martin.jaburek@cah.cz wrote:
So it did not help. Statistics just showed, that it ran for 11300 sec. It screwed all other switches.
What ran for 11300 seconds?
I removed them from nav now.
The settings or the switches?
Is it possible to do some lightweight monitoring (excluding LLDP and other extended functionality, just basic traffic monitoring) If it would help, then we can keep adding features (MAC, vlans, etc.)
ipdevpoll's jobs are fully configurable through ipdevpoll.conf. Each job consists basically of a series of collector plugins to run, and an interval for each job run per device.
Job names can be edited, or you can disable jobs entirely by commenting them out or changing the name of the job section to something that doesn't begin with `job_` (I personally like to prefix the name with an underscore to disable it).
The list of plugins run by each job can also be edited, but its best to understand what each plugin does before experimenting with it. Switch forwarding tables (cam), CDP and LLDP are all collected by the topo job, and each one has a separate plugin, so editing the plugin list here should be easy enough.
When it comes to the inventory job, it all depends on what you mean by "basic traffic monitoring".
Topology job ran that long.
I removed these few switches from NAV.
This I can understand, but is it possible to run different jobs for some switches? I do like topo job generally, but I cannot run it for just a few of them.
By basic traffic monitoring - I mean to do inventory (to get a list of ports) and then traffic port statistics
Brgds
Mat -----Original Message----- From: Morten Brekkevold [mailto:morten.brekkevold@uninett.no] Sent: Thursday, April 10, 2014 11:05 AM To: JABUREK Martin Cc: nav-users@uninett.no Subject: Re: Problem retrieving port statistics
On Tue, 8 Apr 2014 10:33:53 +0000 "martin.jaburek@cah.cz" martin.jaburek@cah.cz wrote:
So it did not help. Statistics just showed, that it ran for 11300 sec. It screwed all other switches.
What ran for 11300 seconds?
I removed them from nav now.
The settings or the switches?
Is it possible to do some lightweight monitoring (excluding LLDP and other extended functionality, just basic traffic monitoring) If it would help, then we can keep adding features (MAC, vlans, etc.)
ipdevpoll's jobs are fully configurable through ipdevpoll.conf. Each job consists basically of a series of collector plugins to run, and an interval for each job run per device.
Job names can be edited, or you can disable jobs entirely by commenting them out or changing the name of the job section to something that doesn't begin with `job_` (I personally like to prefix the name with an underscore to disable it).
The list of plugins run by each job can also be edited, but its best to understand what each plugin does before experimenting with it. Switch forwarding tables (cam), CDP and LLDP are all collected by the topo job, and each one has a separate plugin, so editing the plugin list here should be easy enough.
When it comes to the inventory job, it all depends on what you mean by "basic traffic monitoring".
-- Morten Brekkevold UNINETT
-
 martin.jaburek@cah.cz
martin.jaburek@cah.cz -
Martin.Jaburek@cah.cz
-
 Morten Brekkevold
Morten Brekkevold